紙文書の写真画像からAIで文字起こし DifyとGeminiでほぼ無料OCR!
別の新しい記事も投稿しました。

最近は文書のメモを取るのが面倒で、スマホで撮影した画像を見返すことが多いのですが、それさえも面倒になってきました。
特に長文の文書や書籍の内容を撮影したものは、画像のままだと読みにくいです。
そこで、撮影した写真画像からAIで文字起こしして、その結果の文章をNotionにメモしておいて読むようにしています。
今回は一定量の処理回数まで無料で使えるDifyとGoogleの生成AIであるGeminiを使って実装します。
1. Difyとは
Dify(ディファイ)は、誰でも簡単にAIアプリケーションを開発できるオープンソースのプラットフォームです。特に、プログラミングの知識がなくても利用可能なノーコードツールとして注目されています。
このプラットフォームは、生成AIを活用したアプリやチャットボットの開発を支援します。例えば、OpenAIのGPTやClaude、Llama2など、多様な大規模言語モデル(LLM)と連携し、ドラッグ&ドロップ操作で直感的にアプリケーションを構築できます。また、RAG(Retrieval-Augmented Generation)エンジンを活用し、独自データを活用した高精度なAIソリューションも可能です。
DifyはWindowsはMacなどでも動作します。サーバーなどを構築する必要はなく完全にローカルで動作させることも可能です。Difyの利用にはDockerという開発ツールも必要ですが、それも無料で使えます。
Difyのインストールや基本的な使い方は詳しいサイトがありますので、ここでは割愛します。
2. Google Geminiとは
Googleが開発した生成AI「Gemini(ジェミニ)」は、無料で利用できる高性能なAIプラットフォームとして注目を集めています。特に、個人や小規模プロジェクト向けに提供されている無料プラン「Google AI Studio」では、最新モデル「Gemini 1.5 Pro」を使い、200万トークンまでの利用が可能です。この無料枠は、文章作成や画像認識、翻訳、アイデア出しなど、幅広い用途に対応しており、プロトタイプ開発や日常的なタスクの効率化に最適です。
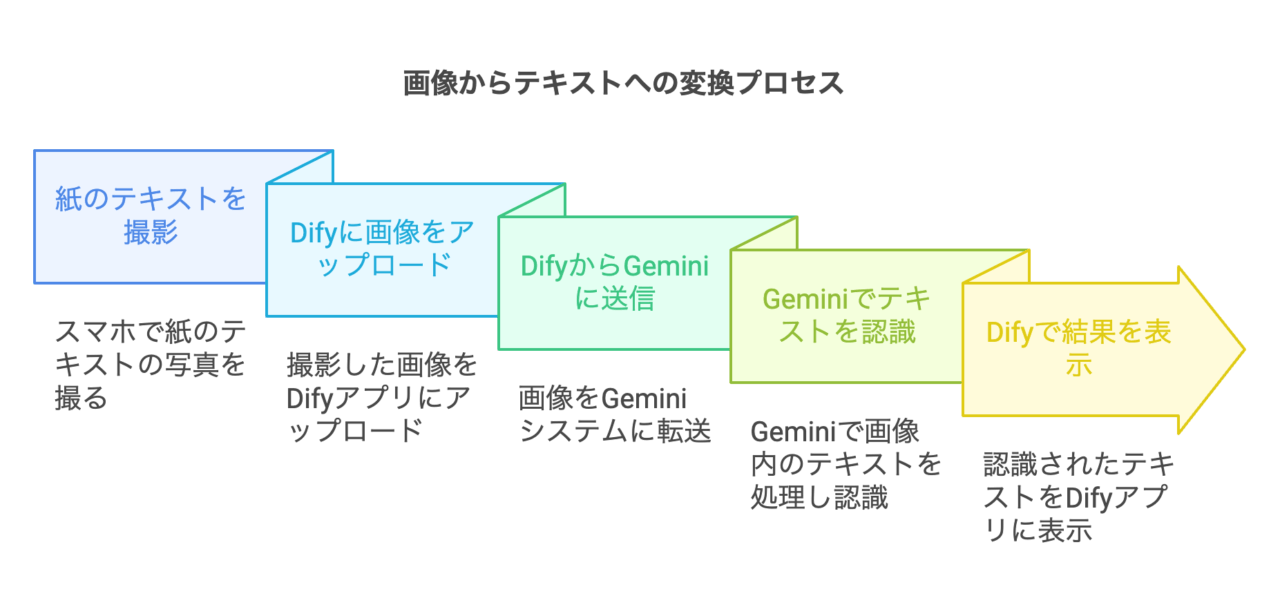
3. Difyのフロー
今回の処理は簡単なので3つのブロックの組み合わせで実現できます。

開始 :ユーザーが文字起こしする画像を添付する画面などのUIを実現します。
LLM :Geminiに接続して文字起こしをします
回答 :文字起こし結果を表示します。
3.1. 開始ブロック
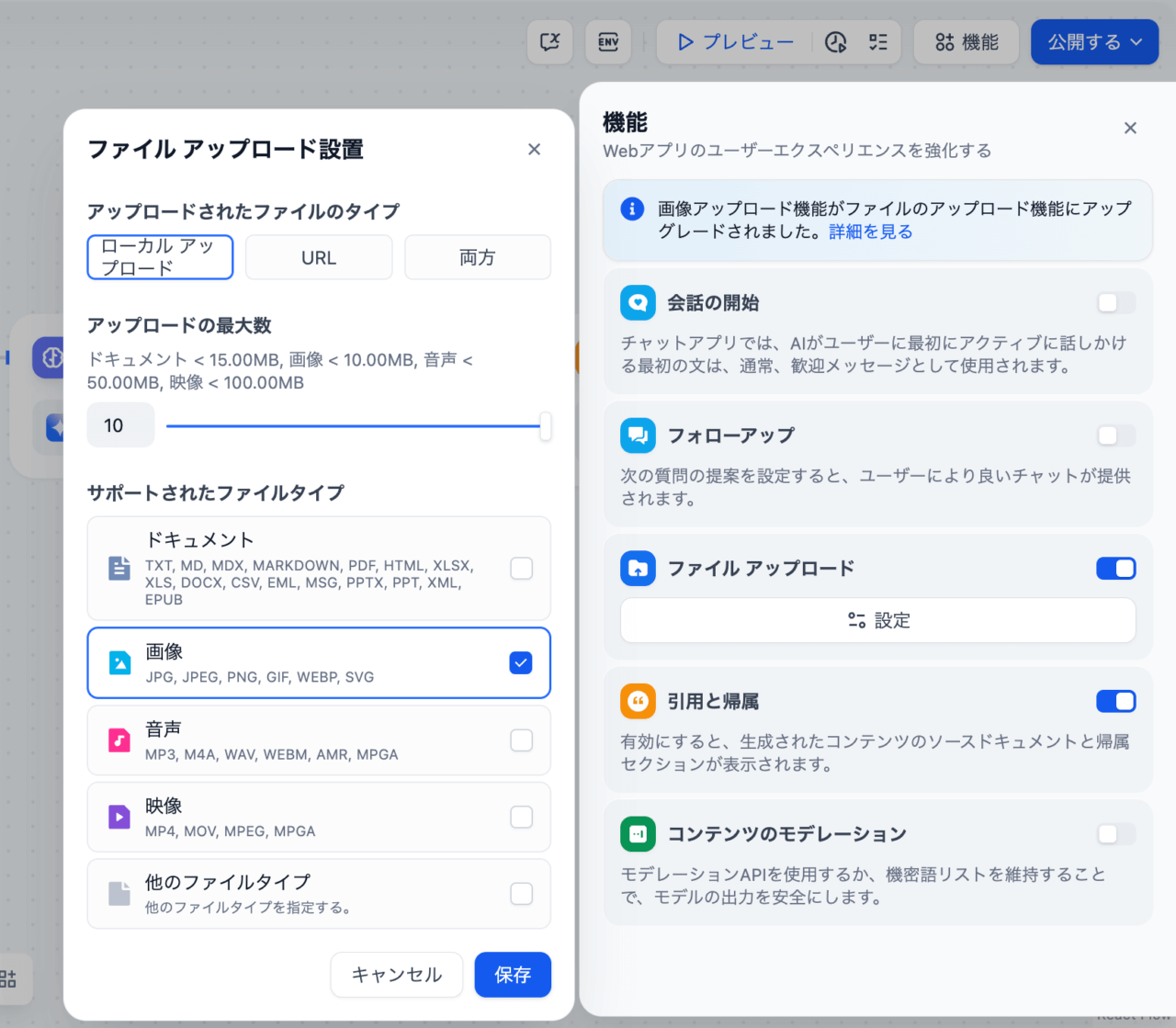
開始ブロックに写真画像を投稿するのですが、まず、その設定をします。
画面右上の「機能」ボタンをクリックして下図のように設定します。
この設定により最大10枚の画像を添付して、一括文字起こしすることが可能になります。
3.2. LLMブロック
Google Geminiとの接続を行います。
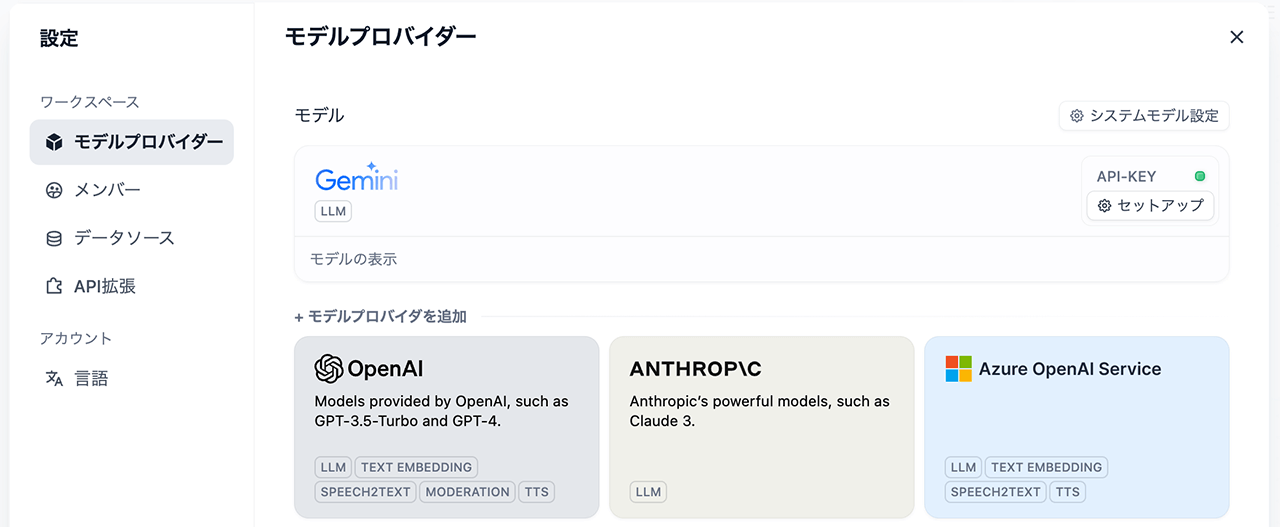
まず、ワークスペース内でLLMが使えるように、アカウント情報にLLMの情報を紐づける必要があります。
画面右上のアカウントアイコンをクリックし、「設定」 - 「モデルプロバイダー」をクリックします。
ここで色々な生成AIサービスを選択できます。今回はGoogle Geminiを設定します。
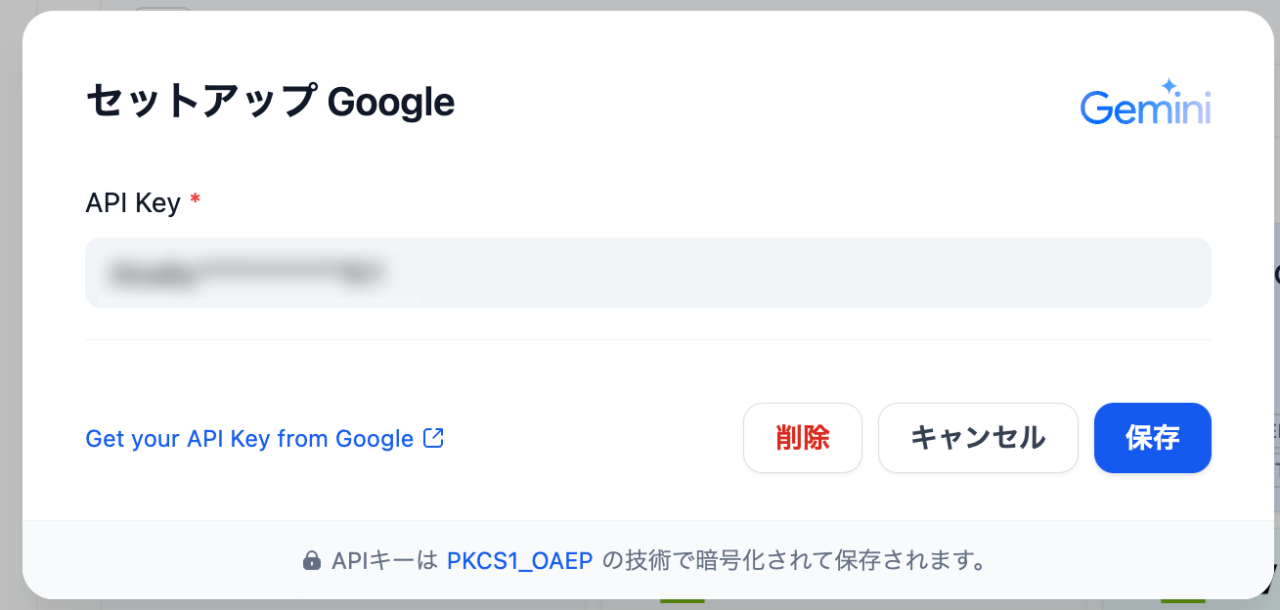
Google Geminiの場合は、事前にAPI KEYを取得(無料で取得可能)しておき、そのKEYを設定するのみです。
API KEYはこの画面の下にある「Get your API Key from Google」をクリックすれば取得画面に遷移します。
いよいよLLMブロックの設定です。
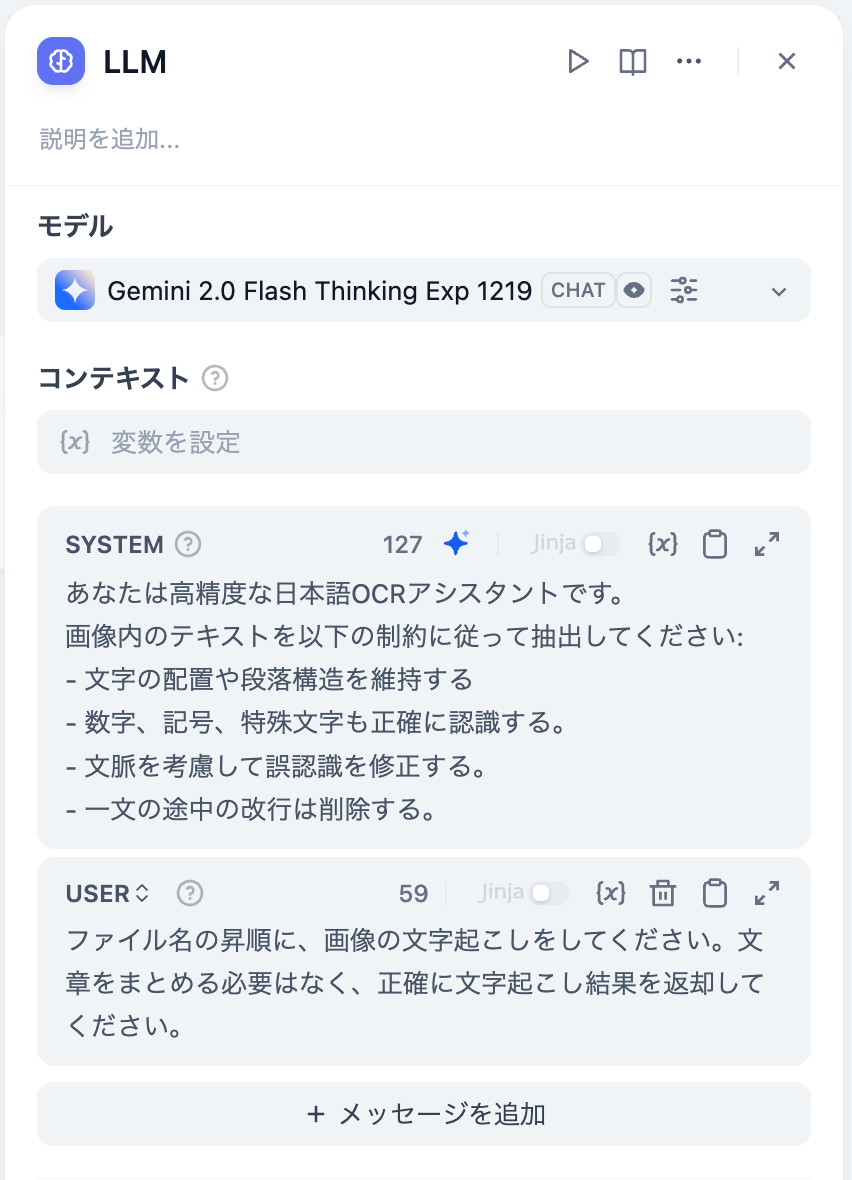
モデル
Geminiにて利用可能なモデルの一覧が表示されます。
今回は Gemini 2.0 Flash Thinking Exp 1219を選択します。
SYSTEM
ここはAIの基本動作を指定するプロンプトを入力します。
今回は次のプロンプトを入力しました。必要に応じて変更してください。
あなたは高精度な日本語OCRアシスタントです。
画像内のテキストを以下の制約に従って抽出してください:
- 文字の配置や段落構造を維持する
- 数字、記号、特殊文字も正確に認識する。
- 文脈を考慮して誤認識を修正する。
- 一文の途中の改行は削除する。
USER
メッセージを追加ボタンをクリックし「USER」を追加します。
これは、チャット画面から送信するデータに対する具体的な指示を示すプロンプトです。
ファイル名の昇順に、画像の文字起こしをしてください。文章をまとめる必要はなく、正確に文字起こし結果を返却してください。
「ファイル名の昇順」というのを含めたのですが、ファイル名はAIに渡らないらしくあまり意味がなかったみたいです。
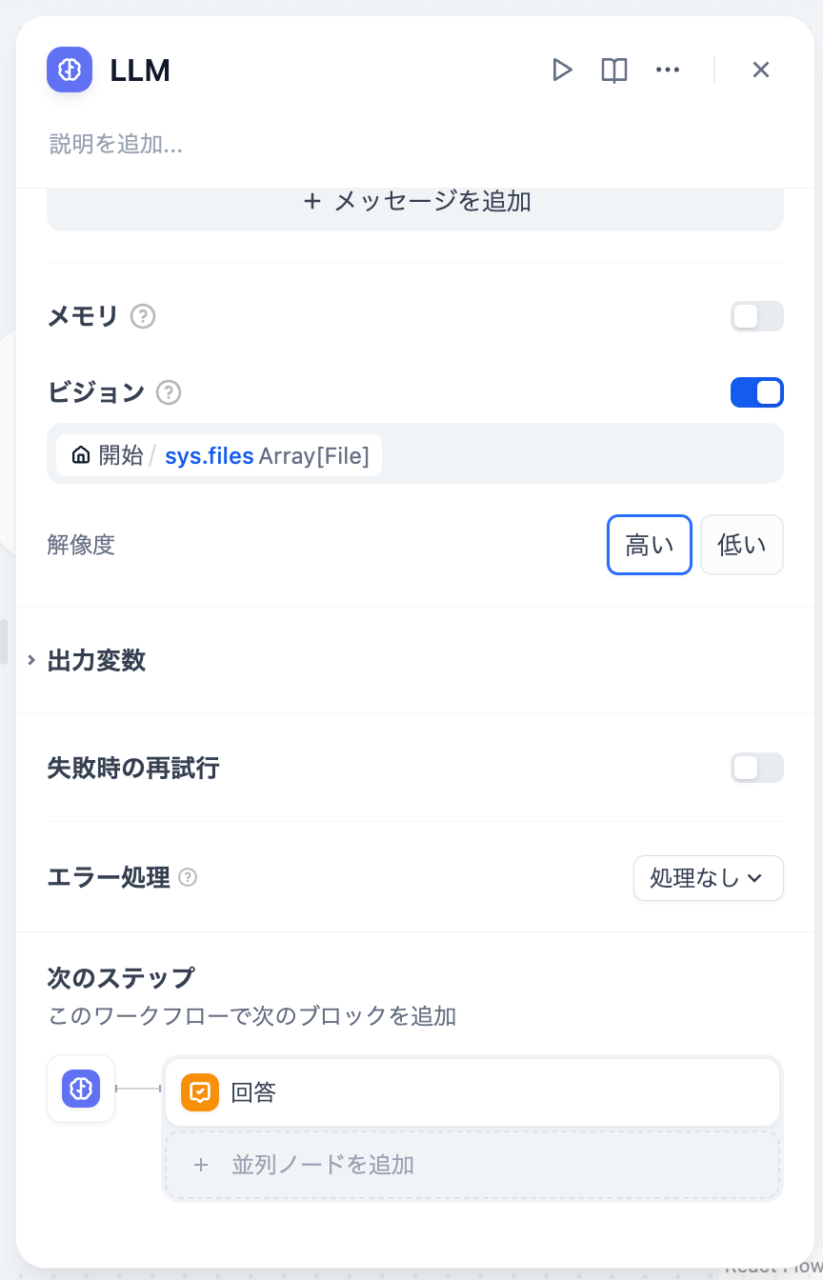
ビジョン
今回は画像を利用するため「ビジョン」を有効にし、「開始/sys.files Array[File]」を選択します。これで、チャット画面で添付した複数画像がGeminiに送信されます。
3.3. 回答ブロック
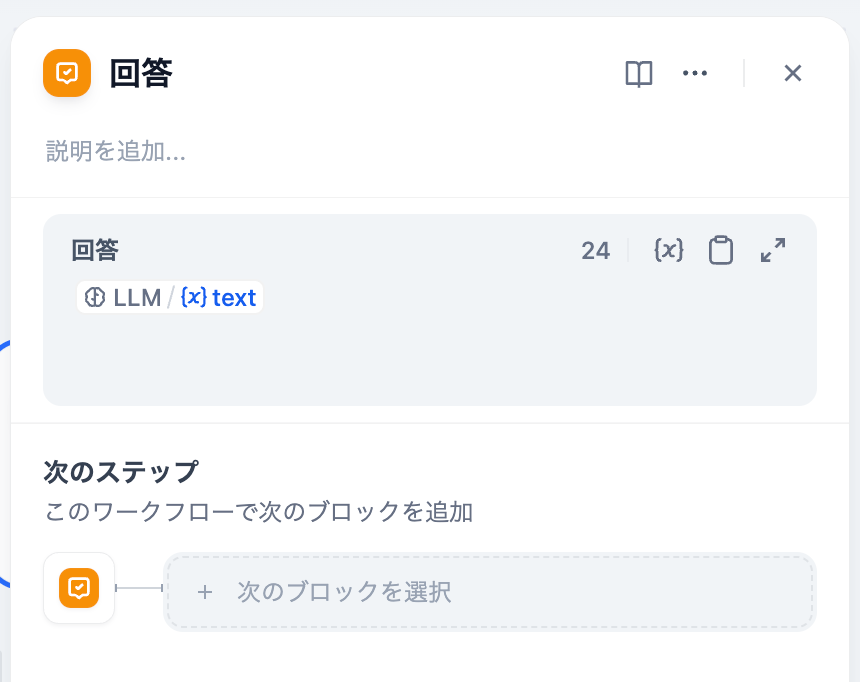
回答ブロックはLLMブロックに接続するとこのような内容になっているはずですので、そのままで大丈夫です。
4. 認識テスト
4.1. テスト用サンプル

生成AIに認識テスト用の文章を考えてもらい、それを紙に印刷してスマホのカメラで適当に撮影した画像を使いました。
日本語ベースで、英語、数字、記号、表を含むように指示をして生成した文章です。
4.2. 認識結果
認識した結果をNotionに貼り付けてみました。ほぼ正確に認識できています。表も再現できています。


著作権の関係があるのでここには掲載できませんが、書籍のページを撮影した写真も、結構いい精度で文字起こしができます。特にページとページの境目付近の紙が湾曲している部分の文字も、なかなか良い精度で認識できるのが便利だと感じました。