1枚の画像から3D化!ComfyUIにてStable Video 3DをノートPCで動かす
Stable Video 3D(SV3D)は、Stability AIによって開発された最新のAI技術であり、単一の画像から高品質な3Dモデル動画を生成することができます。
SV3Dには、SV3D_uとSV3D_pの2つのバリアントがあります。SV3D_uはカメラ調整なしで単一画像入力に基づいて軌道動画を生成し、SV3D_pは単一画像と軌道ビューの両方に対応し、指定されたカメラパスに沿った3Dビデオの作成を可能にします。
今回は、ノートPCにて動作しているComfyUIを使って、SV3Dを動かしてみます。
1. ComfyUIのワークフロー準備
下記サイトより、ComfyUIの「SV3D workflow」を入手できます。
jsonファイルをダウンロードできるので、ComfyUIを起動しているWebブラウザ上にドラッグ&ドロップすればフローが読み込まれます。
エラーがでるときは、ComfyUIをアップデートしてみてください。
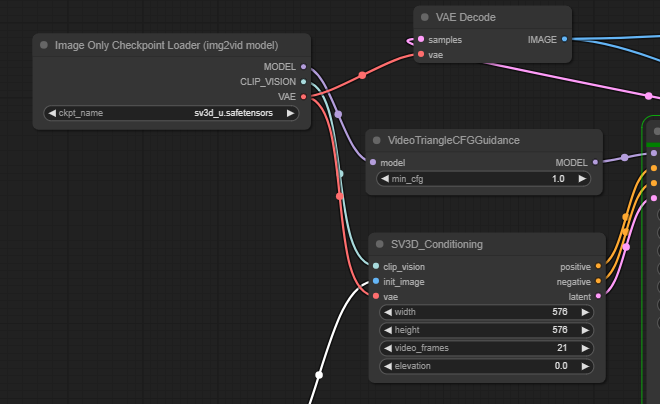
2. ワークフローのカスタマイズ
このワークフローでは、Load CLIP Visionノードにて"pytorch_model.bin"を読み込む設定になっているのですが、入手方法がわからなかったため、次の3つのノードは削除し、代わりに「Image Only Chaeckpoint Load (img2vid model)」を使うようにフローを変更しました。
もしかすると、これが出力結果に何か悪影響を与えるかもしれません。
- Load Checkpoint
- Load CLIP Vision
- Load VAE
3. 出力結果
息子の親友「ゴリちゃん」を真正面から撮影した写真が元画像です。
背景を削除し、入力画像サイズは、 576 x 576 pxです。
ちなみに、出力データを保存する場合には、Vodeo Combineノードの「save_output」をtrueにしてください。
結構、うまく出力できています。


私の画像を使ってみました。少し斜めから撮影した画像のため、左側と右側で結構差があります。
服はうまく背面も再現できています。