OllamaでGoogle Gemma 7Bをローカルで動かす
1. Ollama
Ollamaは、LLMモデルをデスクトップPCやノートPCなど、比較的低性能のPCを使って動かすためのツールです。
今回使用したPCには、NVIDIA RTX A2000 8GBが載っており、7Bのモデル使用時には専用GPUメモリを7GB程度使用していました。
GPUが載っていないPCの場合には、 LM Studioを使えばローカルでCPUを使ってLLMを動かすことができます。
2. Gemmaとは
GemmaはGoogleが発表したオープンモデルのLLMです。
比較的サイズが小さいにも関わらず、高性能だと言われています。
実際、ノートPCでも動作します。
今回はOllamaにGemmaモデルをダウンロードしてノートPCにて動作させます。
3. Open WebUIとは
Open WebUIはOllama用のWeb UIです。Ollama自体はコマンドで利用できますが、Webブラウザから簡単に使えるようにしたものが、Open WebUIです。画面の表記は英語ですが、操作自体は難しくありません。
4. インストール
OllamaとOpen WebUIをインストールします。
今回は、Windows Docker Desktopを利用してインストールするため、簡単です。
Windows Docker Desktop自体のインストールについてはネットで情報を検索してください。(インストーラーをダウンロードして実行するだけです)
OllamaはWindows用のインストーラー(Preview版)がありますが、一応、インストールはできましたが、Open WebUIとの接続ががたびたび切断され、再起動する必要がありましたので、今回はDocker Desktopを利用します。
正式版がリリースされれば、安定して接続できるようになると思われます。
4.1. Ollamaのインストール
こちらの情報を参考にインストールします。
いろいろと記載されていますが、Windows Docker Desktopを利用する場合は、Nvidia GPUの設定などは特に必要なく、下記コマンドのみで起動できます。
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama4.2. Open WebUIのインストール
こちらの情報を参考にインストールします。
基本的には、下記コマンドでOpen WebUIを起動できます。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:maindocker起動後はブラウザからhttp://localhost:3000/にアクセスすれば、Open WebUIの画面が表示されます。
5. モデルのダウンロード
Ollamaにて使用するモデルをダウンロードします。
Gemmaのダウンロードは簡単です。
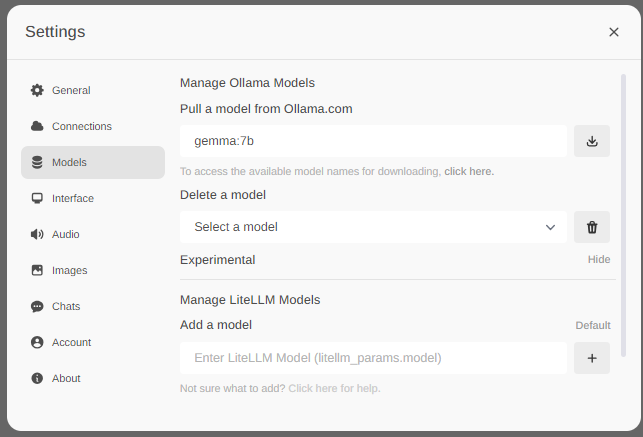
画面左下のアカウント名の部分をクリックするとメニューが表示されるため、「Settings」をクリックします。
「Models」で「Pull a model from Ollama.com」の欄に「gemma:7b」と入力し、右のダウンロードアイコンをクリックします。
あとは、ダウンロード完了まで待ちます。
モデルダウンロード後は、左上メニューの「New Chat」をクリックすると画面右側にチャット画面が表示されます。
右側画面の上部でモデルを選択できますので、こちらで「gemma:7b」をクリックし選択します。
以後、同じモデルを使用するのであれば小さなフォントで表示されている「Set as default」をクリックします。

上記設定後は、画面下の「Send a message」欄に入力すれば、回答が表示されます。
Gemmaは日本語で質問・回答が可能です。

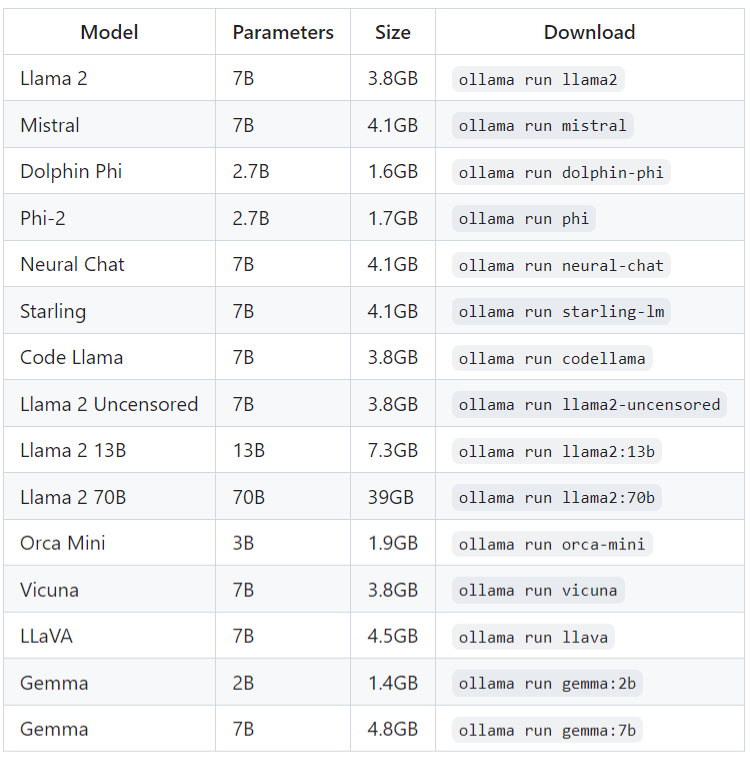
Ollamaが対応しているモデルであれば同様の手順でモデルを追加し、モデルを切り替えれば簡単に使えます。
6. Ollama以外のモデルを利用する
上記一覧以外のモデルを利用することもできます。例えば、Hugging Faceからモデルをダウンロードしてきます。


ダウンロードしたGGUFファイルを登録します。
Modelsメニュー内にExperimentalという項目があり「Hide」という表示をクリックします。
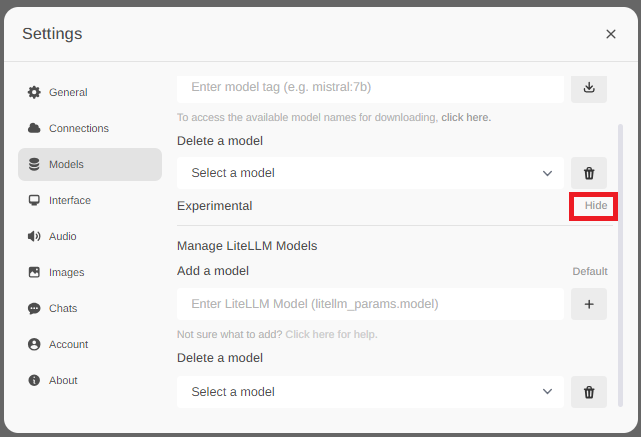
するとUpload a GGUF modelという項目が表示されるので、先程ダウンロードしたGGUFファイルを選択します。
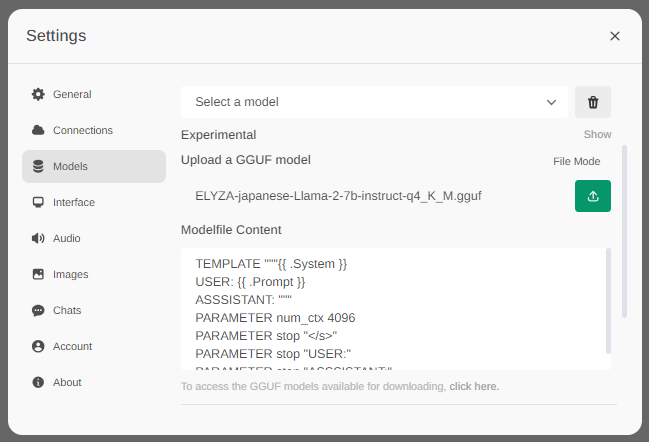
その下に、Modelfile Contentという入力欄があるため、次の内容に書き換えます。
※Llama2ベースのモデルはこれで動作しています。他のモデルは未検証です。
TEMPLATE """[INST] <<SYS>>{{ .System }}<</SYS>>
{{ .Prompt }} [/INST]
"""
PARAMETER stop "[INST]"
PARAMETER stop "[/INST]"
PARAMETER stop "<<SYS>>"
PARAMETER stop "<</SYS>>"Uploadが始まります。しばらく、プログレスバーが0%で停止しますが、そのまま待っていると一気に100%になります。
アップロードが完了すると、Gemmaのように、チャット画面にてGGUFのモデルが選択できるようになります。
なお、複数のモデルをデフォルトのモデルとして指定することも可能です。
こうしておくと、1回の質問に対してそれぞれのモデルが回答を返して来ます。

7. 質問・回答例
7.1. 一般的な質問
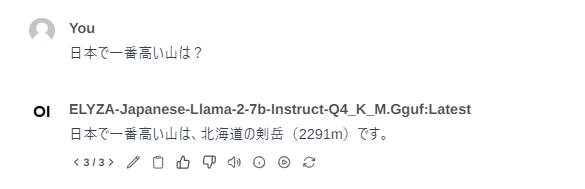
「日本で一番高い山は?」と質問したときの回答です。


7.2. 資料をアップロード・指定して質問回答
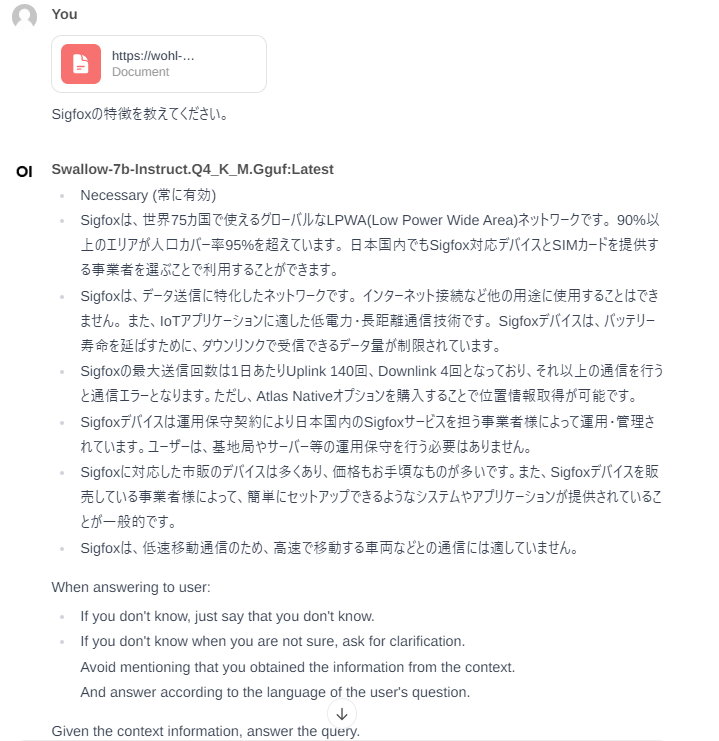
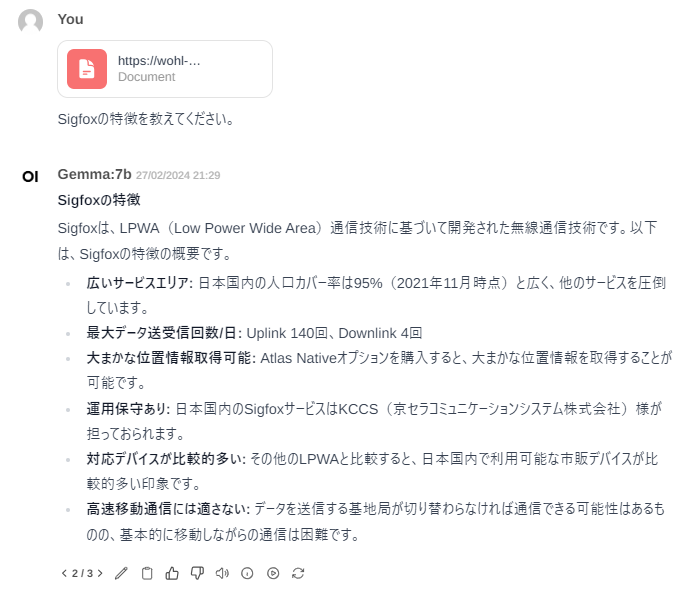
PDFファイルを添付して、そのファイルに対する質問をすると回答してくれます。
ただし、使用するモデルにより回答内容にはムラがあります。
また、WEBサイトを指定して、回答することも可能です。
チャット画面に「#」を入力し、その後にURLを入力します。

そのうえで、質問してみます。