Hagging Faceのモデル(Rakuten AI 7B)をGGUFに変換&4bit量子化してOllamaで動かす。Docker Desktopを使います。
楽天からリリースされた「Rakuten AI 7B」を試してみたかったのですが、Hagging FaceにはGGUFファイルがリリースされていませんでした。
現在はリリースされています!
そこで、Hagging Faceからモデルをダウンロードし、GGUFに変換し、さらに4bit量子化したモデルを作成することにしました。
4bitの量子化はノートPCでもローカルLLMとして動作させるためです。
1. Doker環境構築
今回はWindowsにインストールしたDocker Desktopを利用します。
まず、Dockerfileを作成します。
dockerfile
FROM python:3.9
RUN pip install safetensors huggingface_hub
RUN git clone https://github.com/ggerganov/llama.cpp.git
RUN pip install -r llama.cpp/requirements.txt
WORKDIR /appイメージをビルドします。
docker build -t safetensors-to-gguf .コンテナを起動します。
docker run -it --rm -v $(pwd):/app safetensors-to-gguf bashWindowsの場合、$(pwd)の部分がこのままだと正常に動作しなかったので、絶対パス(C:\project\docker\safetensors-to-gguf\app:)を記入したところ動作しました。パスは各環境に応じて変更してください。
llama.cppをmakeします。
cd /llama.cpp
make2. Hagging Faceからモデルダウンロード
Hugging FaceからRakuten/RakutenAI-7B-chatモデルをダウンローしてきます。
cd /app
git lfs install
git clone https://huggingface.co/Rakuten/RakutenAI-7B-chat※おそらくGitのファイルサイズ制限にひっかかってしまい、モデルファイルのダウンロードに失敗しました。(時間がもったいないので調べてません)
よって、普通にダウンロードして「app/model」ディレクトリ内にHagging Faceの全てのファイルを格納しました。
3. GGUF形式に変換
cd /
python ./llama.cpp/convert.py ./app/model/ --outfile ./app/model-f32.gguf4. 4bitで量子化
./llama.cpp/quantize ./app/model-f32.gguf ./app/RakutenAI-7B-chat_Q4_K_M.gguf q4_K_M5. Ollamaで動かす
OllamaをOpen Web UIで動かします。詳細は下記リンクの記事を参照してください。
GGUFファイルをインポートする際に指定する「Modelfile Content」には次の項目を入力しました。
TEMPLATE """[INST] {{ .System }}
{{ .Prompt }} [/INST]
"""
PARAMETER stop "[INST]"
PARAMETER stop "[/INST]"
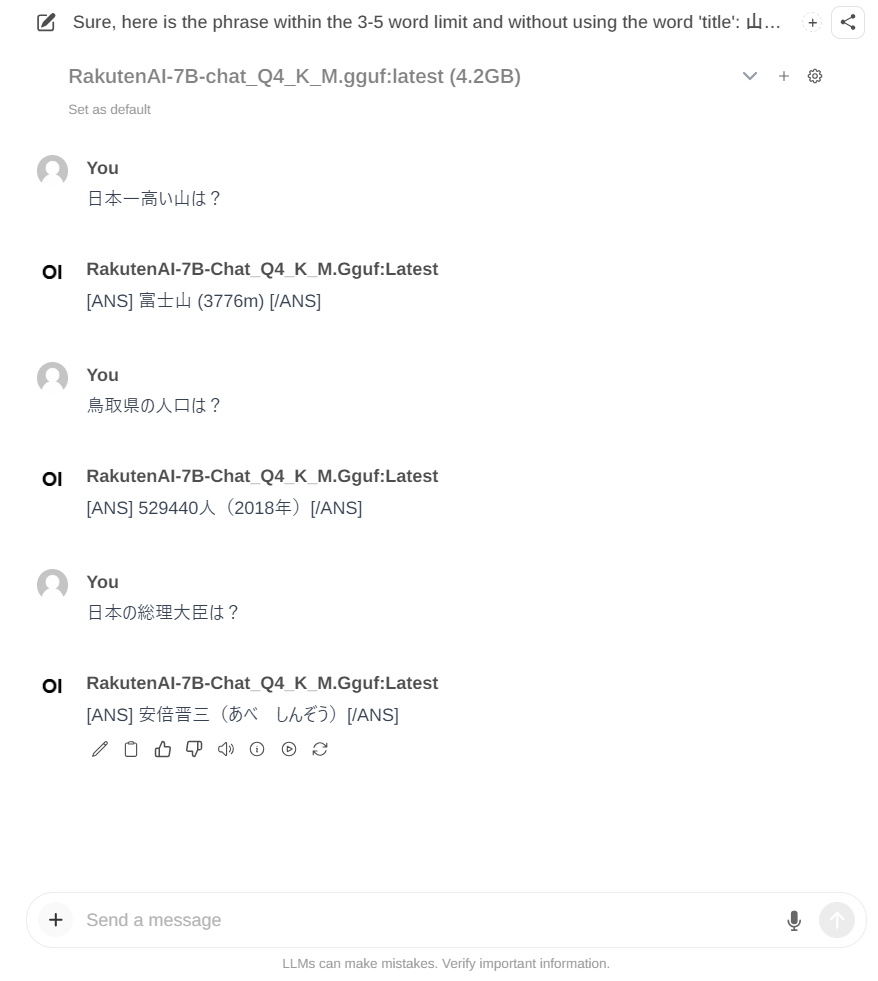
6. 動作確認
それらしい回答ができています。ちなみに、8bit量子化バージョンは総理大臣も回答できていました。