VS Codeで SambaNova Cloudの爆速Llama 3を使ってコード生成
こちらの記事にあるように、SambaNova Cloudは「GPUよりも10倍高速な推論を10分の1の電力で実現」しており、Llama 3シリーズが爆速動作するそうです。そして、今なら無料で使える!これは使ってみるしかありません。

1. SambaNova CloudのAPI Keyを取得
1.1. ユーザー登録
まずはSambaNova Cloudのサイトでユーザー登録をします。
今なら無料で使えます。

1.2. API Key取得
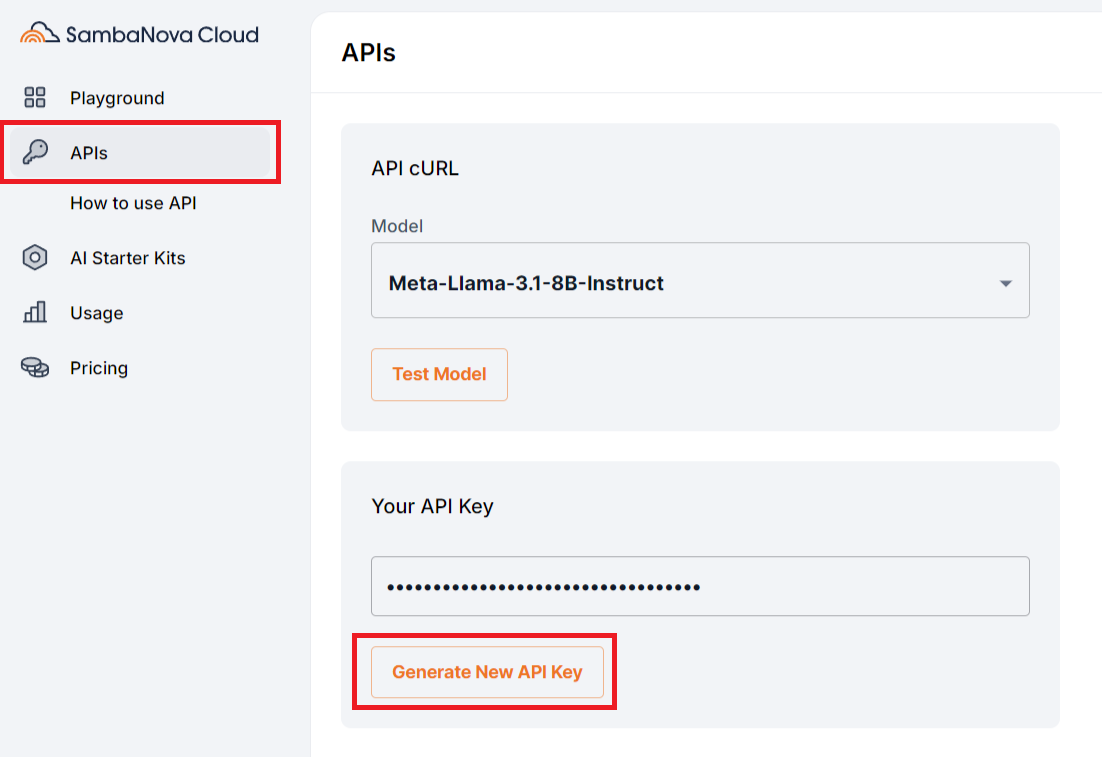
Generate New API KeyをクリックしAPI Keyを取得します。
2. VS CodeにExtensions 「Continue」設定
2.1. インストール
ContinueはVS Codeで様々な生成AIモデルを活用できるようにする機能拡張です。
まずは、Continueをインストールします。
2.2. モデル追加
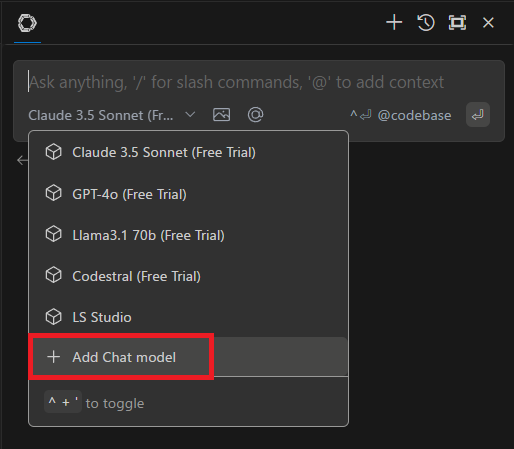
Continueのモデル選択画面で「Add Chat model」をクリックする。
Providerを選択し、API keyを入力し「Connect」をクリック。
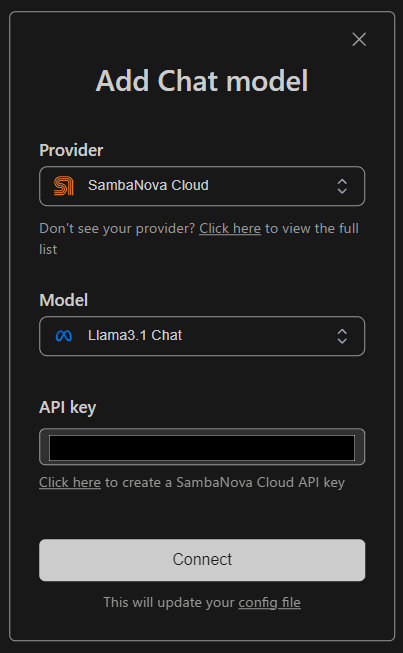
これで「llama3.1-8b」モデルが利用可能になります。
2.3. 利用モデルの変更
デフォルトで設定されるのは「llama3.1-8b」なので、これを別のモデルに変更します。
Continue画面右下にあるギアアイコン(Coinfigure Continue)をクリックすると、Configファイルが開きます。
ここに手動でモデルを追加します。
{
"apiKey": "xxxxxxxxxxx",
"title": "Llama3.1 70B Chat",
"model": "Meta-Llama-3.1-70B-Instruct",
"provider": "sambanova"
},
{
"apiKey": "xxxxxxxxxxx",
"title": "Llama3.1 405B Chat",
"model": "Meta-Llama-3.1-405B-Instruct",
"provider": "sambanova"
}これで、70Bと405Bのモデルも選択可能になります。
レスポンスも早くストレスなく使えます。