
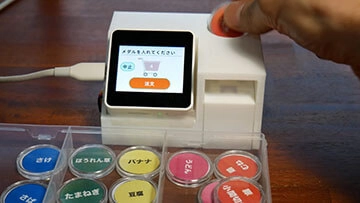


新たなアイデアをカタチにしたい――その挑戦に、私たちは全力でお応えします。
システムの構想段階から、IoTデバイス開発、LPWA通信・クラウドサービスの実装、
そしてスマートフォンアプリ開発まで、ワンストップでサポートします。
Sigfox・Private LoRa・LoRaWAN・LTE-MなどのLPWA通信に対応したデバイスを開発します。
構想段階にあるアイデアを迅速に具現化し、PoCを支援します。プロジェクトの目的を深く理解した上で、検証に必要な最小限の機能を定義し、ハードウェアデバイスの試作から、それを制御・活用するソフトウェアシステムの構築まで、ワンストップで対応可能です。
DX(デジタルトランスフォーメーション)の導入に向けたコンサルティングサービスを提供します。
鳥取県内のお客様を対象に、WEBサイト制作サービスをご提供しています。
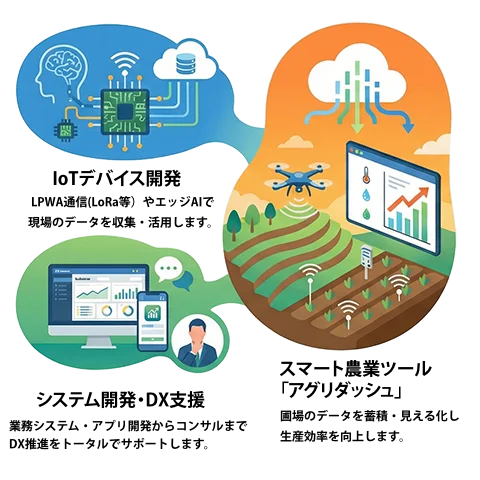
農林水産省「スマート農業技術カタログ」登録

ハウス、圃場からIoTセンサやAIによる画像分析データをLPWA通信にてクラウドへ送信しデータを蓄積、ダッシュボードで見える化します。
VIEW MORE
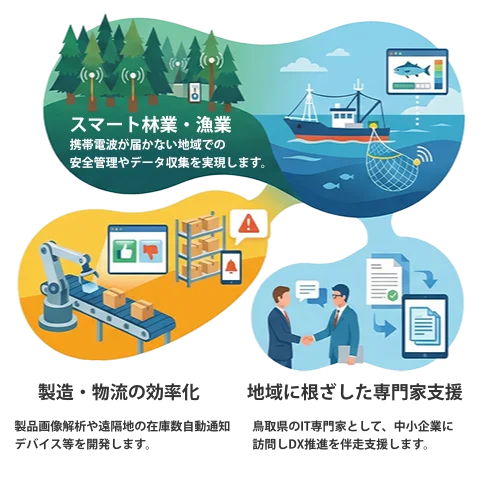
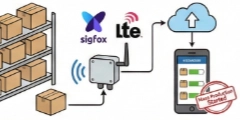
遠隔地の在庫数を自動通知し補充を効率化。

機器制御やデータ分析用アプリの開発。



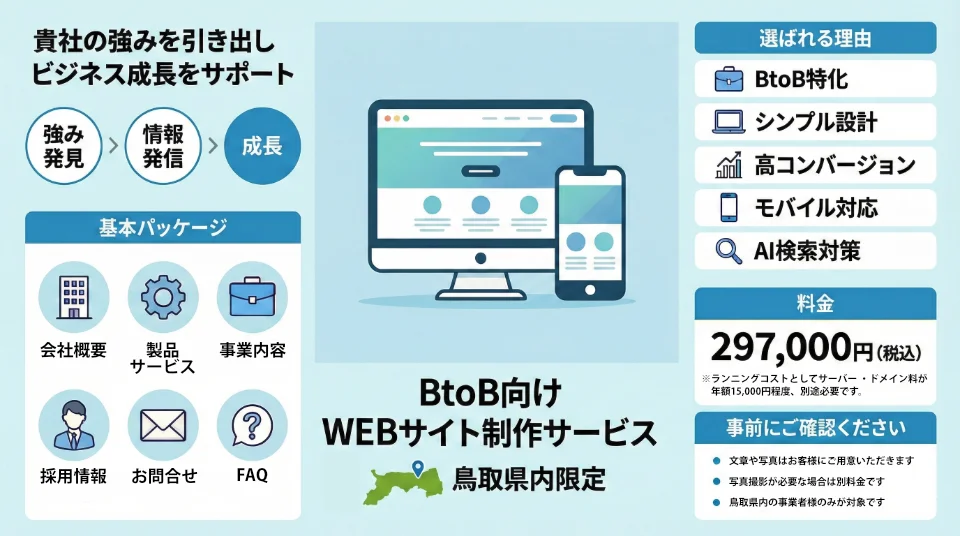
BtoB企業様向けに特化したWEBサイト制作サービスを提供しています。貴社の強みを最大限に引き出し、効果的な情報発信を実現することで、ビジネスの成長をサポートします。
297,000円(税込)
コストパフォーマンスに優れた、高品質なWEBサイトをご提供します。
※ランニングコストとしてサーバー・ドメイン料が年額15,000円程度、別途必要です。
※「小規模事業者持続化補助金」などの各種補助金を活用したWEBサイト制作にも対応可能です。各地域の商工会などと連携し、制作した実績も豊富にございます。
DXの重要性は理解しているものの、社内のIT人材不足で思うように進まない…そんなお悩みはありませんか?
弊社のDX導入コンサルティングサービスなら、限られたリソースでも効果的にDXを推進できます。

| 会社名 |
合同会社ヴォール (WOHL LLC) 私たちの社名「ヴォール」は、ドイツ語で「幸せ」「快適」「繁栄」を意味する「wohl」(ヴォール)に由来しています。 IT技術を単なるツールとして捉えるのではなく、人々の生活を豊かにし、社会全体の成長と調和をもたらしてくれる力だと考えます。この社名には、お客様の事業や社会全体に、より多くの「幸せ」と「繁栄」をもたらしたいという想いが込められています。 |
|---|---|
| 代表者 | CEO 高濱 怜 |
| 所在地 | 〒680-0404 鳥取県八頭郡八頭町見槻中154-2 隼Lab. 2階 |
| 連絡先 |
TEL:050-5212-6328 受付時間:13:00〜17:00 ・初回のお問い合わせは、お問い合わせフォームをご利用ください ・音声ガイダンスにつながりますのでご希望の番号を押してください |
| 設立 | 2018年7月26日 |
| 主要取引先 |
(株)UACJ (株)シーセブンハヤブサ (株)トリクミ (公財)鳥取県産業振興機構 鳥取県商工会連合会 |
| 所属団体等 |
|

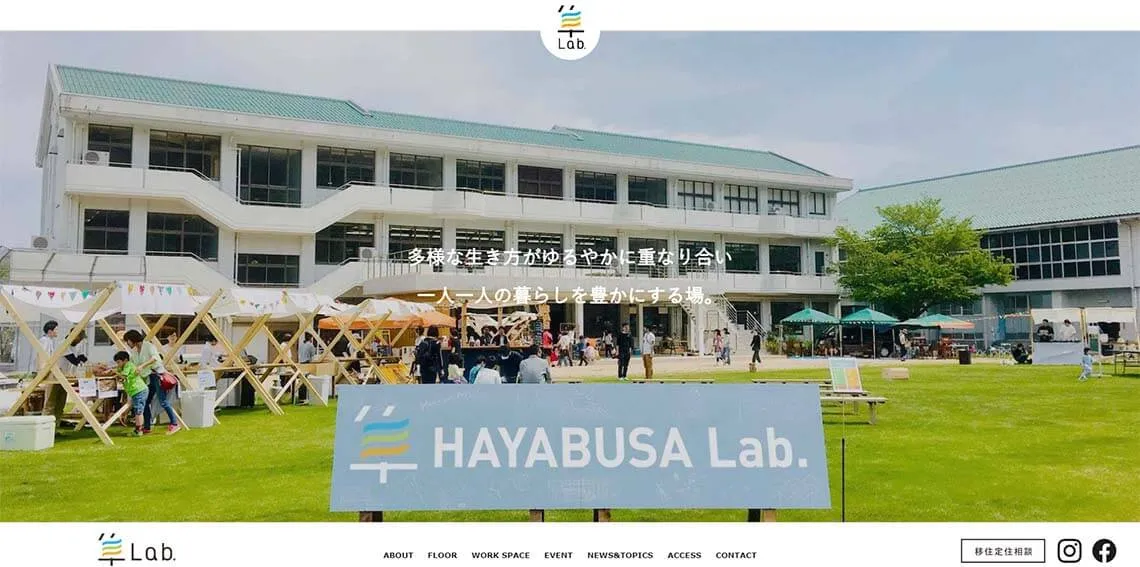
弊社入居施設「隼Lab.」
旧隼小学校をリノベーションしたコミュニティ複合施設
Satoshi Takahama
鳥取の中小企業や個人事業主のIT活用を支援したいと独立・創業しました。DX関連のIoTデバイス開発を主軸に、地域社会に新たな価値と活力を創出したいという想いで取り組んでいます。

お気軽にお問い合せください。
受付時間:13:00〜17:00



