ローカルLLM × リアルタイム検索!Nemotron-Nano-9B-v2-Japanese + LM Studio + Tavily MCP で作るインターネット対応AIアシスタント

この記事でわかること
- LM Studioとは何か、なぜローカルLLMが注目されているのか
- NVIDIA製の日本語特化モデル「Nemotron-Nano-9B-v2-Japanese」の特徴
- MCPとTavilyを使ってインターネット検索機能を追加する手順
- クラウドLLMを使わず完全無料で実現する方法
- 実際に動かすまでの全ステップ
1. はじめに
「ChatGPTは便利だけど、データをクラウドに送りたくない」「月額課金なしで使えるAIが欲しい」そんなニーズに応えるのがローカルLLMです。
今回は、ローカルLLM実行環境の定番ツール「LM Studio」に、NVIDIAが公開したばかりの日本語特化モデル「Nemotron-Nano-9B-v2-Japanese」を組み合わせ、さらに MCP(Model Context Protocol) とWeb検索API「Tavily」を連携させることで、クラウドのLLMを一切使わず、完全無料でインターネットの最新情報を取得して回答できるAIアシスタントを構築しました。
2. 使用したツール・サービスの概要
2.1. LM Studio
LM Studioは、WindowsやmacOSのPC上でLLMをローカル実行するためのGUIアプリです。インストールするだけで、Hugging FaceなどのオープンモデルをChatGPT感覚で使えるようになります。
- 無料・商用利用可
- LLM推論はすべてローカルPC上で実行(会話内容がクラウドに送信されない)
- インターネット検索はTavily経由で取得(モデル自体はローカルで動作)
- OpenAI互換APIサーバーとして動作させることも可能
- バージョン0.3.17からMCP対応
公式サイト

2.2. Nemotron-Nano-9B-v2-Japanese
NVIDIAが2026年2月に公開した、日本語特化の小型言語モデル(SLM) です。
| 項目 | 内容 |
|---|---|
| パラメータ数 | 約9B(90億) |
| アーキテクチャ | Mamba2-Transformer ハイブリッド |
| コンテキスト長 | 最大128Kトークン |
| 推論速度 | Qwen3-8B比で最大6倍高速 |
| 日本語性能 | Nejumi Leaderboard 4(10B未満)1位 |
| ツール呼び出し | 対応(Function Calling) |
| ライセンス | 商用利用可能 |
このモデルの大きな特徴は、56層中わずか4層だけにAttention層を使い、残りをMamba-2とMLPで構成するハイブリッドアーキテクチャです。これにより、長文処理でも非常に高速に動作します。MCPと組み合わせるのに必要なツール呼び出し(Function Calling)にも対応しており、今回の構成にうってつけのモデルです。
推奨VRAMの目安:
- Q4量子化:8GB VRAM(RTX 3060など)
- Q8量子化:12〜16GB VRAM
2.3. MCP(Model Context Protocol)
MCPはAnthropicが策定したオープンプロトコルで、LLMに外部ツール(検索・ファイル操作・データベースなど)を接続するための標準インターフェースです。LM StudioはMCPホストとして動作し、MCPサーバーと通信することでLLMにリアルタイムの情報取得能力を与えられます。
2.4. Tavily
TavilyはLLM向けに設計されたWeb検索APIです。通常の検索エンジンと違い、LLMが扱いやすい形式で結果を返してくれます。
- 無料枠:月1,000リクエストまで
- クレジットカード:登録不要
- MCPサーバーをリモートで公式提供
- APIキー1本で使える手軽さが魅力
登録URL:

3. 全体の構成イメージ
flowchart TB
subgraph ユーザー
A[あなた]
end
B[LM Studio<br/>MCPホスト]
C[Tavily MCP Server<br/>インターネット検索]
D[Nemotron-Nano-9B-v2-Japanese<br/>日本語で回答生成<br/>※ローカルで実行]
A -->|質問| B
B -->|ツール呼び出し要求| C
C -->|検索結果を返す| D
D -->|最新情報を元にした回答| A4. 構築手順
4.1. 前提条件
- Windows 10/11 または macOS(Apple Silicon/Intel)
- Node.jsがインストール済み(
npxコマンドが使えること) - GPU搭載PC推奨(CPUのみでも動作しますが低速です)
4.2. STEP 1:LM Studioのインストール
- https://lmstudio.ai からLM Studioをダウンロード
- インストーラーを実行してインストール完了
4.3. STEP 2:モデルのダウンロード
- LM Studio左サイドバーの虫眼鏡アイコン(Discover)をクリック
- 検索欄に
Nemotron-Nano-9B-v2-Japaneseと入力 - GGUF形式の量子化モデルを選択してダウンロード
- VRAM 8GB の場合:
Q4_K_Mを選択 - VRAM 12GB以上の場合:
Q8_0を選択(より高品質)
- VRAM 8GB の場合:
4.4. STEP 3:Tavily APIキーの取得
- https://app.tavily.com にアクセスしてアカウント登録
- ログイン後、ダッシュボードに表示される APIキー(
tvly-xxxxxxxxxxxx形式)をコピーしてメモしておく
4.5. STEP 4:mcp.jsonの編集(Tavilyの設定)
LM StudioにTavily MCPサーバーの情報を登録します。
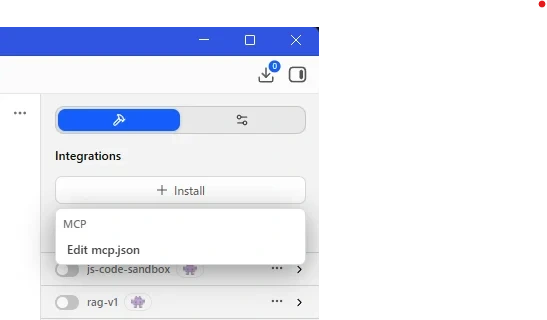
4.5.1. 開き方
- LM Studio右上の ハンマー(?)アイコン(Integrations) をクリック
- 「Install」ドロップダウンをクリック
- 「Edit mcp.json」を選択
エディタが開きます。
4.5.2. 記述内容
以下の内容をまるごとコピーして貼り付けます。
tvly-xxxxxxxxxxxxxxxx の部分は自分のAPIキーに書き換えてください。
{
"mcpServers": {
"tavily-remote": {
"command": "npx",
"args": [
"-y",
"mcp-remote",
"https://mcp.tavily.com/mcp/?tavilyApiKey=tvly-xxxxxxxxxxxxxxxx"
]
}
}
}Saveで保存します。
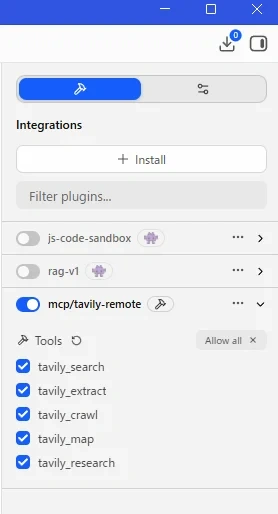
4.6. STEP 5:MCPサーバーの有効化確認
- Integrationsの一覧に
mcp/tavily-remoteが表示されていることを確認 - トグルスイッチをオンにする
- 初回は
mcp-remoteパッケージのインストールが自動で走ります(少し時間がかかります)
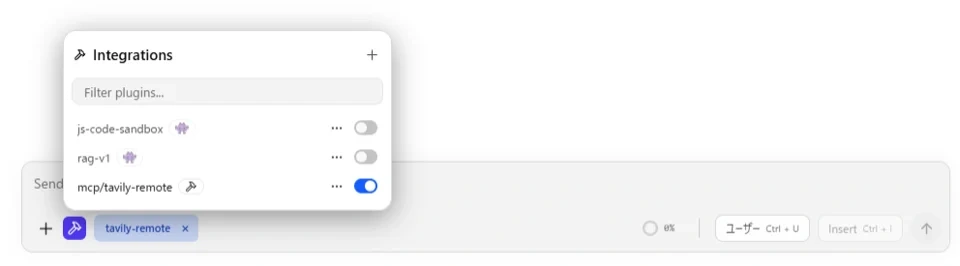
4.7. STEP 6:モデルの読み込みとチャット開始
- 左サイドバーのチャットアイコンをクリック
- 上部のモデル選択から
Nemotron-Nano-9B-v2-Japaneseを選択 - コンテキスト長を 8192〜16384 に設定(MCP使用時はトークン消費が多いため)
- 入力欄の下部に
mcp/tavily-remoteのトグルが表示されていることを確認する。表示されていなければ、ハンマーアイコンをクリックしてONにする。
これで準備完了です!
5. 動作確認
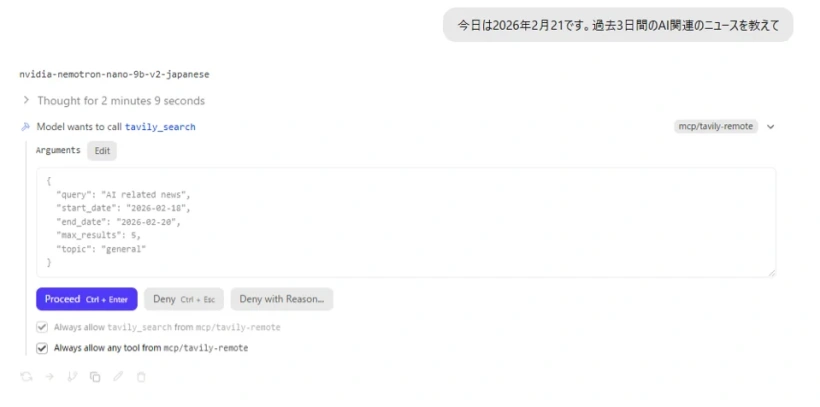
以下のような質問を送ってみましょう。
今日は2026年2月21です。過去3日間のAI関連のニュースを教えてモデルがTavilyのツールを呼び出し、インターネットを検索して最新情報を取得した上で日本語で回答してくれます。
ツール呼び出し確認ダイアログが表示された場合は、引数を確認して 「Allways allow any tool from mcp/tavily-remote」 にチェックし 「Prodeed」 をクリックします。

mcp.jsonへの追記(既存の mcpServers オブジェクトに追加):
"time": {
"command": "uvx",
"args": [
"mcp-server-time",
"--local-timezone",
"Asia/Tokyo"
]
}6. 運用上のポイント
6.1. コンテキスト長の設定
MCP検索を複数回呼び出すセッションでは、検索結果がコンテキストに積み重なってトークンを消費します。コンテキスト長は最低でも 8k(8192トークン)、できれば 16k以上に設定することを推奨します。Nemotron-Nano-9B-v2-Japaneseは最大128Kトークンのコンテキストをサポートしているので、長いリサーチ作業でも安心です。
6.2. MCPトグルの使い分け
すべての質問でインターネット検索する必要はありません。一般的な知識の質問ではMCPトグルをオフにすることで、応答速度が上がり、Tavilyの無料枠を節約できます。
7. まとめ
今回構築したシステムの最大の特徴は、OpenAIやAnthropicなどのクラウドLLMを一切使わず、完全無料で実現できる点です。
- LLM推論はローカルPC上のみで完結:会話内容が外部サーバーに送信されない
- Tavilyの無料枠(月1,000リクエスト):個人利用・検証用途には十分な量
- LM Studio・モデル・MCPプロトコル:すべて無料で利用可能
- Nemotron-Nano-9B-v2-Japanese:9BクラスでNejumi日本語ランキング1位、ツール呼び出し対応
- MCP + Tavily:プロトコル経由でインターネット検索をLLMに接続し、リアルタイム情報を取得可能に
「AIにかけるコストを削減したい」「会話データをクラウドに渡したくない」という要件を同時に満たせるのが、このローカルLLM × MCP構成の強みです。ぜひ試してみてください。
8. FAQ
- Node.jsをインストールしていないとMCPは使えませんか?
- はい、今回の手順で使用している npx コマンドを実行するには Node.js のインストールが必要です。公式サイト(nodejs.org)からLTS版をインストールしてください。
- GPU(VRAM)が足りない場合、動作しませんか?
- PUのみでも動作しますが、推論速度は大幅に低下します。VRAMが不足する場合は、モデルの量子化サイズを下げて(例:Q2_Kなど)ダウンロードするか、LM Studioの「GPU Offload」設定でレイヤー数を調整してメインメモリ(RAM)を併用してください。
- mcp.json を書き換えたのに検索機能が有効になりません。
- SONの構文エラー(カンマの不足、括弧の閉じ忘れなど)が原因であることが多いです。また、APIキーが tvly- で始まっているか、前後に余計なスペースが入っていないか再確認してください。設定後はLM Studioの再起動、またはMCPサーバーの「Reload」を試してください。
- Tavilyの無料枠(月1,000リクエスト)を超えたらどうなりますか?
- 索リクエストがエラーとなり、モデルはインターネット上の最新情報を取得できなくなります。その場合は、MCPのトグルをオフにして、モデルが持つ学習知識の範囲内でのみ利用するように切り替えてください。
- なぜコンテキスト長を8k〜16k以上に設定する必要があるのですか?
- MCP経由で検索を行うと、検索結果(Webサイトの抜粋テキストなど)が大量のトークンとして会話履歴に追加されます。コンテキスト設定が短いと、検索結果を入れた瞬間に過去の会話を忘れてしまうため、余裕を持った設定が推奨されます。
- 他の日本語モデル(Llama-3ベースなど)でも同じことができますか?
- はい、可能ですが、そのモデルが 「Function Calling(ツール呼び出し)」 に対応している必要があります。対応していないモデルの場合、検索が必要な場面で適切なMCPコマンドを発行できず、検索が実行されません。
- 回答の生成が途中で止まってしまいます。
- LM Studioの右パネルにある設定で「Hardware Settings」の「GPU Offload」を最大化しているか確認してください。また、トークン制限(Max Tokens)の設定が小さすぎないか確認し、必要であれば値を大きくしてください。